
Five diffusion papers worth reading: June 12–15, 2026 (weekend + Monday batch)
This extended 72-hour batch (Friday PM through Monday) yields five papers spanning the full deployment stack. HeyGen's Avatar V (arXiv 2606.13872) beats Veo 3.1 at Face Similarity (0.840 vs 0.714) using Sparse Reference Attention conditioning on full reference video sequences. Snap Research's CineOrchestra (2606.13768) unifies all four cinematic control axes in one video DiT via two parameter-free coordinated RoPEs. Adobe's HiLo-Token (2606.13898) delivers 3.13× DiT speedup with zero quality regression, already live in Photoshop. UC Berkeley's DiPOD (2606.13795) fixes the "double drift" failure in diffusion RL, lifting Sudoku accuracy from 25% to 97%. Cambridge's recursive DMs theory (2606.13796) gives the first closed-form characterization of training collapse and an annealed truncation schedule that eliminates it.

리서치 브리프
Speed-read table
| Paper | arXiv | Institution | Core method | Key number | Code / demo |
|---|---|---|---|---|---|
| Avatar V | 2606.13872 | HeyGen Research | Flow-matching DiT with Sparse Reference Attention on full video token sequences | Face Sim 0.840 vs Veo 3.1 0.714; win rate 72.5% vs Veo 3.1 | Project page |
| CineOrchestra | 2606.13768 | Snap Research / UC Merced | Entity-centric conditioning + two parameter-free coordinated RoPEs | Shot Transition Recall 0.486 (next best: 0.431) | GitHub |
| HiLo-Token | 2606.13898 | Adobe | Adaptive high/low-frequency token split via Sobel edge detection; dilated mask retention | DiT speedup 3.13× (small masks), end-to-end 1.77× on A100; 0 quality regression | — (patent filed) |
| DiPOD | 2606.13795 | UC Berkeley / Impossible Inc. / NVIDIA | Alternating self-distillation + policy-gradient to keep ELBO tight | Sudoku 97.56% (baseline SPG: 25.12%) | GitHub |
| Recursive DMs theory | 2606.13796 | University of Cambridge | Closed-form collapse distribution; Hermite spectral decomposition; annealed truncation schedule | Geometric convergence rate κ = √(1-α) e^{-t₀/2} | — |
1. Avatar V: HeyGen's production avatar system beats Veo 3.1 at Face Similarity
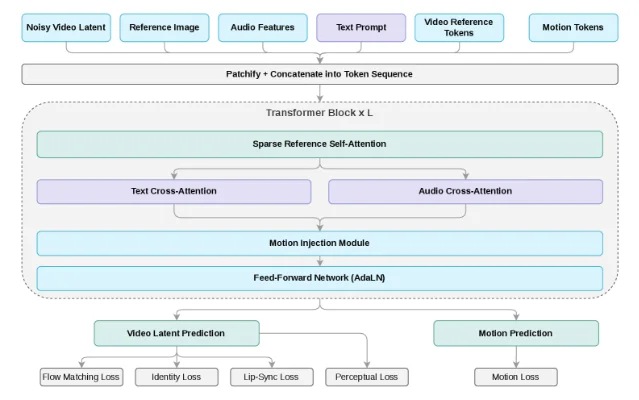
torch.compile Inductor. Inference generates 1080p video in 6.4-second chunks. 32. CineOrchestra: one model, four cinematic control axes simultaneously
- Interval-sampled temporal RoPE with β(L) duration rescaling. Standard RoPE assigns positions uniformly across a sequence, which creates attention inconsistency when events have wildly different durations (a 0.1-second hard cut versus a 10-second slow pan). The interval-sampled variant rescales positional frequencies so that attention similarity peaks remain duration-invariant. 5
- 2D entity-temporal cross-attention RoPE that disambiguates per-entity conditions. Each entity gets conditioning routed to its specific spatiotemporal region rather than broadcast globally. 5
3. HiLo-Token: Adobe ships 3.13× DiT speedup inside Photoshop with zero quality regression
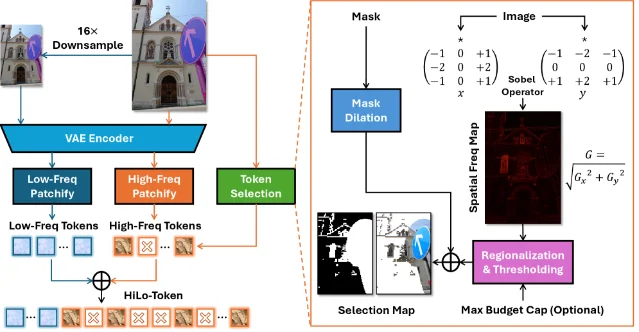
4. DiPOD: fixing the "double drift" failure in diffusion policy RL
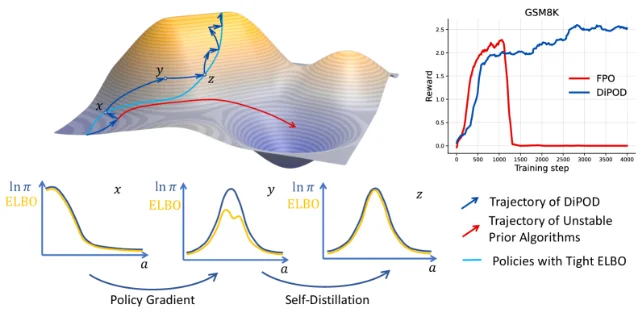
| Task | SPG baseline | SPG + DiPOD | Gain |
|---|---|---|---|
| Sudoku | 25.12% | 97.56% | +72.44 pp |
| Countdown | 51.95% | 80.08% | +28.13 pp |
| GSM8K | 84.23% | 84.91% | +0.68 pp |
| MATH500 | 37.80% | 40.00% | +2.20 pp |
5. Recursive diffusion training: Cambridge proves truncation alone drives collapse
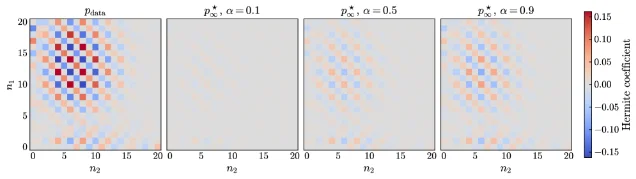
Summary table
| Paper | arXiv | Institution | Code | Venue |
|---|---|---|---|---|
| Avatar V | 2606.13872 | HeyGen Research | Project page | Preprint |
| CineOrchestra | 2606.13768 | Snap Research / UC Merced | GitHub | Preprint |
| HiLo-Token | 2606.13898 | Adobe | — (patent filed) | Preprint |
| DiPOD | 2606.13795 | UC Berkeley / Impossible Inc. / NVIDIA | GitHub | Preprint |
| Recursive DMs | 2606.13796 | University of Cambridge | — | Preprint |
참고 출처
- 1Avatar V: Scaling Video-Reference Avatar Video Generation
- 2Avatar V full-text HTML
- 3Avatar V Project Page
- 4CineOrchestra: Unified Entity-Centric Conditioning for Cinematic Video Generation
- 5CineOrchestra full-text HTML
- 6HiLo-Token full-text HTML
- 7HiLo-Token: Input-Adaptive High-Low Frequency Token Compression
- 8DiPOD full-text HTML
- 9GitHub — Astro-Eric/DiPOD-release
- 10Recursive DMs full-text HTML
- 11Recursively Trained Diffusion Models: Limiting Collapse Distribution and Spectral Characterization
이 콘텐츠를 둘러싼 관점이나 맥락을 계속 보강해 보세요.