
Five diffusion papers worth reading: June 17, 2026
DAR 8.75× speedup, NoiseTilt 20× NFE cut, R-MDMs 5× param savings, 2 ICML 2026

研究速览
Wednesday's batch drew 179 cs.CV and 294 cs.LG new submissions. Of ~29 diffusion-titled papers, five are worth your time: two ICML 2026 acceptances that cross-listed today, a training-acceleration result that halves the convergence budget for SiT, a reward-guided sampler that matches 500-NFE baselines at 25 steps, and a new scaling axis for masked diffusion models that lets a 10.6 M-parameter model beat a 53 M-parameter baseline on structured reasoning tasks.
Speed-read table
| # | Paper | arXiv | Institution | One-line highlight |
|---|---|---|---|---|
| 1 | DAR | 2605.20708 | Alibaba + NJU + ZJU + CityU HK | Learnable cross-layer routing replaces fixed residual; FID 9.67 → 7.56, 8.75× training speedup on SiT-XL/2 |
| 2 | NoiseTilt | 2606.18066 | KAIST + U Tokyo | Reward gradients injected into noise term (not mean); 25 NFE beats best 500-NFE baseline on aesthetic score |
| 3 | R-MDMs | 2606.18022 | EPFL + Cambridge | Recursive depth as third MDM scaling axis; 10.6 M params matches 53.1 M baseline on Sudoku |
| 4 | Attention Sinks | 2605.09313 | University of Utah | Causal removal of DiT attention sinks leaves CLIP-T intact ( |
| 5 | Flash-GRPO | 2605.15980 | ZJU + Tsinghua + Joy Future | Single-step GRPO for video diffusion; VBench Aesthetic 66.43, Subject Consistency 98.70, 6× cheaper than full-trajectory training |
1. Rethinking Cross-Layer Information Routing in Diffusion Transformers (DAR)
arXiv: 2605.20708 (v2, updated June 16) · 12 authors led by Chao Xu and Maohua Li, Alibaba Group / Nanjing University / Zhejiang University / CityU Hong Kong · cs.CV 1
Code/demo: No public GitHub at time of writing (author response on HF: "looking into it").
Peer-review status: Preprint; v2 revision cross-listed June 16.
Core contribution. Standard DiT residual connections sum the current sublayer output with the layer input using a fixed scalar weight of 1. DAR (Diffusion-Adaptive Routing) replaces that fixed sum with a learned softmax-weighted mix of outputs from all preceding sublayers, sampled via a chunk of size S. Three variants are available: static (a per-layer learned vector), timestep-injected (static vector plus the existing adaLN conditioning signal), and dynamic (query projected from the previous sublayer output). The dynamic variant acquires timestep context implicitly through DiT's existing conditioning path without any new architecture module. 2
Key technical insight. The authors diagnose three symptoms in standard DiT residual streams: forward amplitude inflation (~100× between block 1 and block 28), backward gradient attenuation (deep-layer gradients drop more than one order of magnitude), and inter-block redundancy (adjacent block cosine similarity consistently above 0.9). All three point to the same root cause: fixed unit-weight residuals enforce an over-rigid information highway that forces every block's output to dominate the stream. DAR's softmax weighting lets the model dynamically adjust how much weight to place on shallow vs. deep representations depending on the current noise level. 2
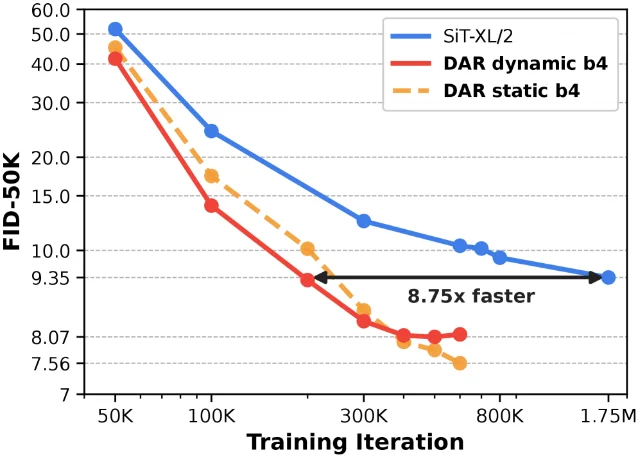
Quantitative results. On ImageNet 256×256 (SiT-XL/2): DAR static chunk-4 reaches FID 7.56 at the same iteration budget where the baseline achieves 9.67. To match the baseline's converged quality, DAR requires 8.75× fewer iterations. Combined with REPA (a representation alignment objective), DAR+REPA at 100K iterations hits FID 7.09 versus REPA-only at 9.89 — roughly a 2× early-training gain. The 200K iteration result (FID 5.92) surpasses REPA-alone at 300K. 2
A community note worth flagging: HF user "parlance" argued the idea of "using existing noise-level conditioning vectors to derive residual stream blending weights is something I've seen in at least half a dozen papers." The authors have not yet responded to the novelty question directly. Treat the 8.75× acceleration figure as the more defensible claim — that's measured on SiT-XL/2 regardless of prior-work genealogy. 3
Why read it. If you train SiT or DiT variants, DAR is a drop-in swap: replace the residual line, pick chunk size S=4, run. The training-time budget reduction is the most immediately actionable result. The REPA compatibility result (DAR + REPA > REPA alone at matched compute) is also worth noting if you already use representation alignment objectives.
2. NoiseTilt: Noise-Tilted Reverse Kernels for Diffusion Reward Alignment
arXiv: 2606.18066 (submitted June 16) · Jisung Hwang, Yunhong Min, Jaihoon Kim (KAIST), I-Chao Shen (University of Tokyo), Minhyuk Sung (KAIST); 5 authors · cs.LG 4
Code/demo: No public repository at time of writing.
Peer-review status: Preprint; 52-page paper.
Core contribution. Reward-guided diffusion sampling faces a structural tension: gradient-based methods (DPS and variants) inject reward gradients into the mean of the reverse kernel, which shifts intermediate samples off the learned data manifold and degrades output quality. Search-based methods (SVDD, BoN) stay on-manifold but discard the gradient signal. NoiseTilt proposes a third option — the Noise-Tilted Reverse Kernel (NTRK) — that routes reward gradients into the noise term instead. Because the perturbed distribution still has the same mean as the base kernel, intermediate samples stay consistent with the pretrained model's learned trajectory. 5
Key technical insight. Injecting an arbitrary gradient vector into the noise term would produce non-Gaussian noise, violating the kernel's assumptions. NTRK solves this with a whitening operator built on two-order statistics (2OS) projection: the reward gradient is transformed into a vector statistically indistinguishable from standard Gaussian noise (cosine similarity to a true Gaussian draw exceeds 0.99999 under 99.99% confidence bounds). The result is that the kernel's stochasticity becomes "tilted" toward the reward direction while remaining formally Gaussian. The method is compatible with any pretrained model and requires no fine-tuning. 5
Quantitative results. On aesthetic generation (FLUX backbone), NTRK at 25 NFE achieves Aesthetic Score 7.4510 — surpassing the best baseline (SVDD) at 500 NFE (7.1363), a 20× reduction in inference compute. Combined with Best-of-N, NTRK at 500 NFE reaches 7.9656. On text alignment, NTRK at 25 NFE achieves PickScore 0.2224, again beating all 500-NFE baselines. For video generation (Wan2.1 backbone), VideoReward scores 3.465 versus DPS at −0.130 and FreeDoM at −0.211. NTRK also stacks on top of fine-tuned models: MixGRPO+NTRK reaches PickScore 0.2545 versus MixGRPO+DPS at 0.2235. 5
Why read it. NTRK is the first method that simultaneously maintains pretrained-model compatibility (no distribution shift from the base kernel) and uses gradient information per step. Table 1 of the paper lays out the taxonomy cleanly: gradient-guided + on-manifold + single-sample-per-step is an unoccupied cell, and NTRK fills it. The whitening operator derivation is the novel mechanism — worth reading if you work on inference-time alignment or reward-guided sampling more broadly.
3. Recursive Scaling in Masked Diffusion Models
arXiv: 2606.18022 (submitted June 16) · Alba Carballo-Castro, Julianna Piskorz, Paulius Rauba, Mihaela van der Schaar, Pascal Frossard; EPFL + University of Cambridge · cs.LG 6
Code/demo: No public repository at time of writing.
Peer-review status: Preprint.
Core contribution. Masked diffusion models (MDMs) currently scale along two axes: parameter count and number of denoising steps T. R-MDMs introduce recursive depth L as a third axis: at each denoising step, the same transformer block is applied L times in sequence, reusing parameters but increasing the effective computation per step. A (K⊗L) model has K shared blocks iterated L times; a (KL⊗1) baseline has KL independent blocks. 7
Key technical insight. Why does recursion help MDMs more than it might help standard transformers? Each recursive loop operates over the full partially denoised sequence using bidirectional attention. Unlike an AR transformer where information flows causally, every token position exchanges information with every other position at every recursive step. This means each loop can refine a global consistency check across the partially unmasked sequence — something that a single-pass forward pass cannot do. The benefit is most pronounced on structured tasks (Sudoku, countdown arithmetic) where iterative constraint propagation maps naturally onto recursive computation; on unstructured text (Text8), the advantage largely disappears (NLL 5.43 recursive vs. 4.74 non-recursive). 7
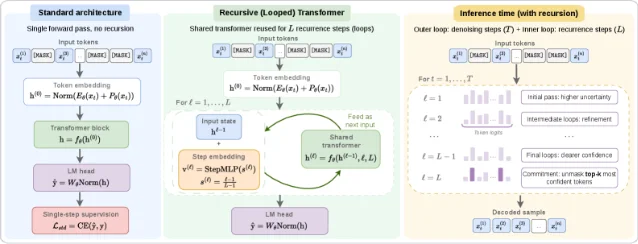
Quantitative results. On Sudoku 9×9 at iso-FLOP budget: the (6⊗5) model with 10.6 M parameters reaches 93.6% valid puzzle rate (VPR) at T=5, outperforming the (30⊗1) baseline with 53.1 M parameters (77.8%). On Countdown-4, a (3⊗5) model (5.5 M params) achieves 70.2% right-token rate (RTR) at T=20, matching the 15-layer baseline (26.7 M params) at 69.4%. Inference compute can also be reduced: a (6⊗5) model with L=3 and T=5 (15 forward passes) reaches 95.6% VPR, matching the non-recursive baseline at T=40 (40 forward passes) — a 2.7× reduction in inference compute. 7
Notably, inference-time recursion can be set independently from training-time recursion. A model trained with L_t=5 can run at L_s>5 at inference, typically improving performance further — up to 97.4–98.2% VPR — beyond what the non-recursive baseline achieves at any step budget. 7
Why read it. The parameter efficiency result (5× fewer parameters, matched performance) matters for resource-constrained deployment of MDMs. The inference-time flexibility (L_s ≠ L_t) is a practical bonus: a single checkpoint becomes a Pareto frontier across latency budgets. The structured-task caveat is important — if your MDM application is natural language, the gains shown here may not transfer.
4. Attention Sinks in Diffusion Transformers: A Causal Analysis (ICML 2026)
arXiv: 2605.09313 (v3, updated June 16; ICML 2026 accepted) · Fangzheng Wu, Brian Summa; University of Utah · cs.CV / cs.LG 8
Code: github.com/wfz666/ICML26-attention-sink (5 stars, 21 commits, OpenReview link public)
Peer-review status: ICML 2026 accepted.
Core contribution. In autoregressive LLMs, a small number of tokens accumulate disproportionately high incoming attention mass ("attention sinks") and are widely believed to be functionally necessary for generation quality. Wu and Summa ask whether the same holds in diffusion transformers, using causal intervention rather than correlation. 9
Key technical insight. Three design differences separate DiT sinks from LLM sinks. First, DiT sinks are dynamic: at each head and each timestep, the top-1 incoming-mass token is identified fresh rather than being pinned to a fixed position. The index-0 overlap rate with LLM-style sinks is below 0.2%. Second, sinks in SD3 are concentrated almost entirely in text conditioning tokens (>99.9% of dynamic sinks map to text token indices 4016–4231), not visual latent tokens. Third, sink mass peaks during early denoising (high noise) and decays as the image becomes cleaner.
The causal test: suppress the top-k sink tokens in layer 12 of SD3, measure CLIP-T, ImageReward, and HPS-v2 on 553 GenEval prompts. For k=1, CLIP-T changes by |Δ|<0.002 (95% CI contains zero), ImageReward and HPS-v2 are equally unaffected. The intuition from LLMs — sinks are functionally necessary — does not hold for semantic alignment in diffusion transformers. 9
Importantly, suppression does cause sink-specific perceptual shifts: for k=1, LPIPS_sink=0.347 versus LPIPS_rand=0.053 for an equal-budget random masking (ΔΔ=+0.295, p<0.0001). This dissociation — perceptual trajectory changes but semantic alignment unchanged — is the paper's sharpest finding. The authors caution that LPIPS/FID_shift in their setup measure deviation from the unsuppressed baseline, not from ground truth; the magnitudes are comparable to swapping the sampler scheduler (FID_shift ~331). 9
Quantitative results. k=1 suppression on SD3: CLIP-T Δ = <0.002 (CI contains zero); ImageReward Δ insignificant; HPS-v2 Δ insignificant. Perceptual LPIPS for k=1: sink-targeted 0.347 vs. random-targeted 0.053 (6× larger). Stronger suppression (k≥10) begins to degrade HPS-v2 (k=10: ΔΔ=−0.005, p=0.007; k=50: ΔΔ=−0.020, p<10⁻⁴), but CLIP-T remains robust throughout. Cross-validated on SDXL with both self-attention and cross-attention. 8
Why read it. The result has practical implications for efficient attention design in DiTs: one frequently cited reason to preserve sink tokens — that they are functionally necessary for semantic alignment — is now causally refuted for k=1 interventions. The code is public, the intervention protocol is clean, and the ICML acceptance provides peer-reviewed backing. Researchers designing sparse or linear attention variants for DiTs should account for these findings.
5. Flash-GRPO: Efficient Alignment for Video Diffusion via One-Step Policy Optimization (ICML 2026)
arXiv: 2605.15980 (v3, updated June 16; ICML 2026 accepted) · Xiaoxuan He, Siming Fu, Zeyue Xue, Bohan Zhuang (corresponding), et al.; Zhejiang University + Joy Future Academy + Tsinghua University; 12 authors · cs.CV / cs.LG 10
Code: github.com/Shredded-Pork/Flash-GRPO (51 stars, 4 forks, 8-GPU and 96-GPU configs)
Peer-review status: ICML 2026 accepted.
Core contribution. GRPO-based alignment of video diffusion models requires rolling out a full multi-step denoising trajectory for each reward evaluation — computationally expensive for long video backbones like Wan2.1. Naive single-step GRPO (selecting one random timestep per update) reduces cost but introduces two failure modes that lead to unstable or collapsed training. Flash-GRPO fixes both with two targeted mechanisms, enabling single-step training that matches or beats full-trajectory methods at 6× lower compute. 11
Key technical insight. The first failure mode: in naive single-step GRPO, all rollouts within a prompt group may be sampled at different timesteps. Advantage estimation then conflates policy quality with noise-level difficulty — a rollout at a high-noise timestep (where the model can do little) appears to have low reward regardless of the policy's actual competence. Iso-Temporal Grouping (ITG) fixes this by ensuring all rollouts within a prompt group share the same timestep, so advantage estimation reflects only policy quality.
The second failure mode: the policy gradient objective contains a time-dependent scaling factor λ(t) = √(Δt/σ_t) + σ_t√(Δt)(1−t)/(2t) whose value varies substantially across timesteps. Without correction, different timesteps contribute wildly different gradient magnitudes, destabilizing training. Temporal Gradient Rectification (TGR) explicitly normalizes this factor, ensuring uniform per-step contribution to parameter updates. 11
Quantitative results. On Wan2.1-T2V-1.3B, trained for 350 GPU-hours (vs. ~2,100 for full-trajectory Flow-GRPO): 11
| VBench metric | Flash-GRPO | Flow-GRPO (full trajectory) |
|---|---|---|
| Aesthetic Quality ↑ | 66.43 | 65.79 |
| Subject Consistency ↑ | 98.70 | — |
| Object Class ↑ | 90.00 | — |
| Imaging Quality ↑ | 68.28 | 68.60 |
HPSv3 eval reward: naive single-step = 4.64 → +ITG = 5.31 → +ITG+TGR = 5.42, with only the full Flash-GRPO achieving training stability (no reward collapse). Flow-GRPO-Fast1 (a fast variant) suffers catastrophic reward collapse around 300 GPU-hours; Flash-GRPO maintains monotonic reward growth. Results scale to Wan2.1-14B, where Flash-GRPO remains stable and converges faster than full-trajectory Flow-GRPO. 11
Why read it. The mechanism paper is straightforward: two identified failure modes, two targeted fixes, both ablated cleanly (the +ITG, +TGR ablation in the HPSv3 curve gives you each contribution separately). The 6× compute reduction makes reward-based video diffusion fine-tuning feasible on smaller clusters. Code supports both 8-GPU and 96-GPU configurations, so the barrier to replication is low.
Reading order recommendation
For most researchers: start with Attention Sinks (ICML 2026, compact paper, clean causal experiment, directly relevant to anyone working on efficient DiT attention). Then Flash-GRPO (ICML 2026, the ablation design is a template for RL alignment work, and the 6× compute result changes what's practical). NoiseTilt third if reward-guided sampling or inference-time alignment is in your scope — the whitening operator derivation is the densest section but the payoff (20× NFE reduction) is large. DAR fourth if you train SiT/DiT from scratch and want a drop-in training accelerator; hold off until a public codebase appears for independent verification of the novelty question. R-MDMs last unless you specifically work on discrete or masked diffusion for structured reasoning tasks — the parameter efficiency result is striking but the Text8 caveat limits applicability to unstructured language.
Cover: AI-generated.
围绕这条内容继续补充观点或上下文。